Underpass Data Flow¶
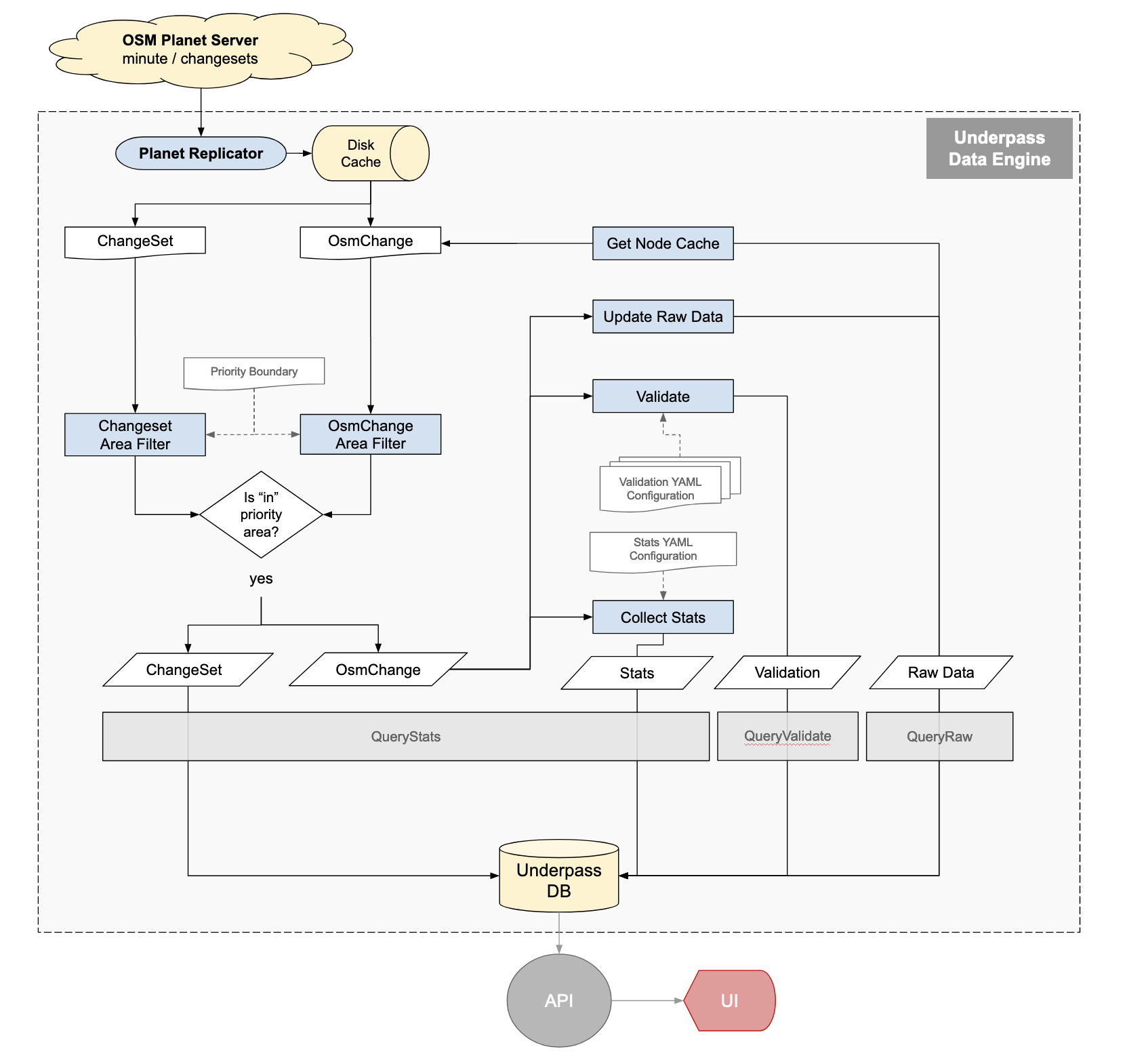
The Overpass data storage contains information from several sources. Underpass has to duplicate this collection of data and aggregate it into a similar structure. The primary data is the map data itself, which contains no history or change data. All the necessary data is available from planet.openstreetmap.org, but is not all in the same format, and is in different places on the planet server. There appear to be no open-source projects that aggregate all this data together other than Overpass.
There are two different change file formats. One includes the hashtags and comments from the change. The other is the changed data itself. Both of these data files can be downloaded from the planet server, and can also be updated with minutely changes. There is currently no open source software that I can find to process the changeset file, nor to merge it with the other change data. This is one of the tasks Underpass needs to handle. To support the Missing Maps leaderboard, and OSM Stats. the changes are used to calculate the totals of highways, waterways, and buildings added or edited in that change. A change it the data at uploading to OSM time. Underpass will recreate the history as it processes the change files.
For producing statistics, the process initially starts by downloading the large data file of all changes made since 2005. As hashtags didn’t exist until late 2014, data prior to then is ignored. Starting in 2014, hashtags were stored in the comments field of the map data, till the hashtag field was added in late 2017. This data file has some of the fields we want, which is documented here.
Briefly, Underpass extracts the hashtag (if there are any) and changeset timestamp. The next task is to download the changed data itself. This is available at planet.openstreetmap.org as well. The osmium program can do this, but does not support importing it into a database. It only works with disk files. The Replicator program will do a similar task, namely download the changes, but will apply them to the statistics database. While Replicator processes the changes, it will also update the statistics database by adding the totals for the new data to the existing amounts. For statistics collection, the core OSM database isn't needed.
However the changes do need to be applied to the OSM map database, so when processing exports, or later doing validation, it’s up to date. The entire update process of both databases has to happen within one minute if we want to update that frequently, which is the goal. When updating the map database, any node or way that is changed will be stored in the database in a new table. This will create the history needed for augmented diffs. Only the previous version is stored, any older entries will be deleted from the history database.
Source Data¶
Underpass collects data from multiple sources, primarily the Change Files from the OpenStreetMap planet server. Changes are availble with different time intervals. The minutely one are the primary data source. There are two sets of minute update, one documents the change and the other is the changed data itself.
Directory Organization¶
Almost all directories and files are numerically based. The very top level contains the intervals, and the changeset directories, and looks like this:
minute/
changeset/
hour/
day/
Under each one of these top level directories are the numerical ones. At the lowest level there are 1000 files in each directory, so the value is always a consistent 3 digit number.
...
002/
001/
000/
Under each on of these sub-directories are the actual data ones
999/
998/
...
001/
000/
Each one of these directories contains 1000 files, roughly 16 hours of data.
replication/002/
replication/002/002/
replication/002/002/002/
replication/002/002/002/
replication/002/002/002/002.state.txt
replication/002/002/002/002.osm.gz
The state file contains the ending timestamp of the associated data file. Underpass uses the state.txt file to find the right data. THe timestamps are not a consistent time interval, so it's not really possible to just calculate the right data file. To speed up searching for the right data file based on a timestamp, Underpass downloads them and enters the path to the data file and the timestamp into postgres.
This process works forward and backwards. When initializing a database from scratch, Underpass will just bulk download the state files, starting with the most recent ones, and then going backwards in time. It takes about a week to download all the minutely state.txt files, hourly only a few hours.
Underpass can also monitor for new data files, so as to keep up to date. If the database is up to date, the threads are put to sleep, and wake up a minute later to see if there are new files. If behind by several minutes, Underpass will bulk download them until caught up.
Underpass uses simple threading, so can utilize multiple CPU cores. When a new data file is downloaded, it's uncompressed and parsed. During the parsing process, some data validation is done. If a change fails validation, it's written to a database table so a validator can look into the issue later. If it passes validation, then statistics are calculated, and written to the database.
Output Databases¶
Underpass currently writes to 1 primary database: the underpass database, which stores all the calculated statistics, data validation results and raw OSM data that also gets updated every minute.